XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~
第8回 XMLDBのデータモデルと再現性
インフォテリア株式会社 野中康弘 NONAKA, Yasuhiro
今回はXMLデータの入出力として、XMLDBにデータを格納する場合に使用されるデータモデルについて解説します。代表的な3種類のデータモデル(XPath、DOM、XML Information Set(InfoSet))の概要と特徴、XMLDBからデータを取り出す際のXMLデータの再現性について取り上げます。今回の内容はXMLDBを選定する際に必要な知識となりますので、しっかりと理解を深めておきましょう。
XMLDBのデータモデル
本連載の第1回で、「XMLDBはXMLデータモデルでデータの格納/操作が行なえるデータベース」「XMLデータモデルとはXMLデータの論理構造のこと」と解説しましたが、皆さんは覚えていますか。
基本的に、XMLデータをXMLDBに格納する際は、XMLDBに組み込まれているパーサーが解析を行なってツリー構造など(データモデル)に変換し、格納します(図1)。
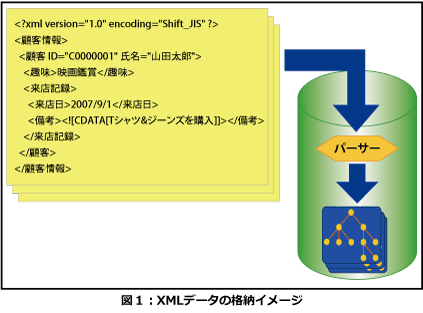
- XPathベースのデータモデル
- DOMベースのデータモデル
- XML Information Set(InfoSet)ベースのデータモデル
LIST1:顧客情報XMLデータ
<?xml version="1.0" encoding="Shift_JIS" ?>
<顧客情報>
<顧客 ID="C0000001" 氏名="山田太郎">
<趣味>映画鑑賞</趣味>
<来店記録>
<来店日>2007/9/1</来店日>
<備考><![CDATA[Tシャツ&ジーンズを購入]]></備考>
</来店記録>
</顧客>
</顧客情報>XPathベースのデータモデル
XPathでは、表1に示す7種類のノードが定義されています。
表1:XPathのノードの種類
| ノードの種類 | 説明 | 持つことのできる子ノード |
| ルート | 文書全体 | 要素、処理命令、コメント |
| 要素 | 要素 | 要素、テキスト、処理命令、コメント |
| 属性 | 属性 | なし |
| 名前空間 | 名前空間 | なし |
| 処理命令 | 処理命令 | なし |
| コメント | コメント | なし |
| テキスト | 要素の内容の文字列 | なし |
- XML宣言をノードとして扱わない
- CDATAセクションをノードとして扱わないので、CDATAセクション内の文字は文字データとしてテキストノードにまとめられる
- 属性ノードは要素を親ノードとするが、要素の子ノードではない
- ルートノードが先頭になる
- 要素ノードはその子ノードよりも前になる
- 先に開始タグが出現した要素ノードが前になる
- 属性ノードは親要素となる要素ノードの子ノードよりも前になる
- 属性ノード同士の順序は実装に依存する
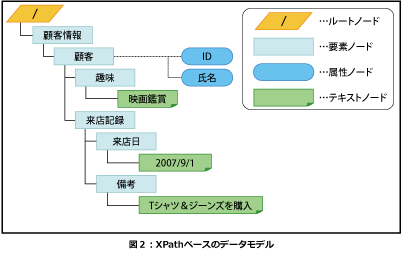
では、「備考」要素ノードはどのようになるでしょうか。顧客情報XMLデータの「備考」要素の内容はCDATAセクションとして記述されていますが、XPathのモデル化の中で『CDATAセクションをノードとして扱わないので、CDATAセクション内の文字は文字データとしてテキストノードにまとめられる』と定義されていますので、「備考」要素ノードもテキストノードを持ちます。またXPathベースのデータモデルでは、XMLデータに含まれる無意味な空白文字(改行、行送り、タブ、半角スペース)を削除しません。
DOMベースのデータモデル
DOMには表2に示す12種類のノードがあり、XPathのノードよりもXMLデータに忠実にモデル化できます(表3)。
表2:DOMのノードの種類
| ノードの種類 | 説明 | 持つことのできる子ノード |
| Document | 文書全体 | Element(最大1つ)、ProcessingInstruction、Comment、DocumentType(最大1つ) |
| DocumentFragment | 一時操作用の文書ツリー | Element(最大1つ)、ProcessingInstruction、Text、Comment、CDATASection、EntityReference |
| EntityReference | 実体参照 | Element、ProcessingInstruction、Text、Comment、CDATASection、EntityReference |
| Element | 要素 | Element、ProcessingInstruction、Text、Comment、CDATASection、EntityReference |
| Attribute | 属性 | Text、EntityReference |
| DocumentType | 文書型宣言 | なし |
| ProcessingInstruction | 処理命令 | なし |
| Comment | コメント | なし |
| CDATASection | CDATAセクション | なし |
| Entity | 実体 | なし |
| Notation | 記法 | なし |
| Text | テキスト | なし |
表3:XPathとDOMのノードの対応
| DOM | XPath |
| Document | ルート |
| DocumentFragment | - |
| EntityReference | - |
| Element | 要素 |
| Attribute | 属性 |
| DocumentType | - |
| - | 名前空間 |
| ProcessingInstruction | 処理命令 |
| Comment | コメント |
| CDATASection | - |
| Entity | - |
| Notation | - |
| Text | テキスト |
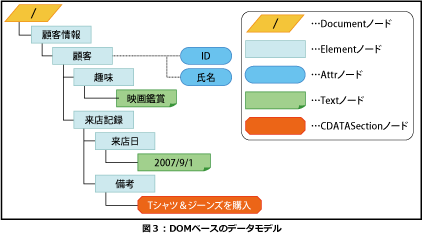
ここで挙げている例以外にも、XMLデータ内に文書型宣言が記述されている場合にも違いがあり、XPathベースのデータモデルでは文書型宣言をノードとして扱いませんが、DOMベースのデータモデルの場合には文書型宣言をDocumentTypeノードとして扱います。
また、DOMベースのデータモデルでのXMLデータに含まれる無意味な空白文字(改行、行送り、タブ、半角スペース)の削除については、XPathベースのデータモデルとは異なり、削除しても削除しなくてもかまいません。DOMベースのデータモデルを採用する製品の実装に依存します。
名前空間の扱いについては、XPathベースのデータモデル、DOMベースのデータモデルでは、名前空間情報が要素ノード、属性ノード情報内に含まれている点では同じです。XPathではさらに名前空間コンテキストをノードにしています。XPathベースのデータモデルとDOMベースのデータモデルの違いを表4にまとめましたので、参照してください。
表4:XPathベースのデータモデルとDOMベースのデータモデルの違い
| XPath | DOM | |
| CDATAセクションの扱い | テキストノードにまとめる | CDATASectionノードとして扱う |
| 文書型宣言の扱い | ノードとして扱わない | DocumentTypeノードとして扱う |
| 余分な空白文字の扱い | 削除しない | 削除するかしないかは実装に依存 |
| 名前空間の扱い | 要素ノード、属性ノード内に名前空間情報を持ち、さらに名前空間ノードを持つ | 要素ノード、属性ノード内に名前空間情報を持つ |
InfoSetベースのデータモデル
XML Information Set(InfoSet)ベースのデータモデルは、XPathベースのデータモデルやDOMベースのデータモデルとは異なり、XMLデータを抽象的な構造で表現するデータモデルです。この抽象的な構造を用いることで、XPathやDOMなどの仕様で定義されている情報の互換性を保つことができるようになります。
XPathベースのデータモデルやDOMベースのデータモデルでは「ノード」を使って表現していましたが、InfoSetベースのデータモデルでは「情報項目」を使って表現し、「情報項目」は複数のプロパティから構成されています。InfoSetで定義されている情報項目を表5に、主な情報項目のプロパティを表6~9にまとめていますので参照してください。
表5:InfoSetの情報項目の種類
| 情報項目の種類 | 説明 |
| 文書情報 | 文書全体 |
| 要素情報 | 要素 |
| 属性情報 | 属性 |
| 処理命令情報 | 処理命令 |
| 展開されない実体参照情報 | プロセッサによって展開されなかった実体参照 |
| 文字情報 | 要素内の1文字ごとの情報(文字参照やCDATAセクションを含む) |
| コメント情報 | コメント |
| DOCTYPE宣言情報 | DOCTYPE宣言 |
| 解析対象外実体情報 | 解析対象外実体 |
| 記法情報 | 記法 |
| 名前空間情報 | 名前空間 |
表6:文書情報項目の主なプロパティ
| プロパティ | 説明 |
| document element | ドキュメントエレメントに該当する要素情報項目 |
| children | ドキュメント順で付けられた子となる情報項目のリスト |
| notations | 1つ1つのDTDの中で宣言された記法を表す記法。情報項目の順序なしセット |
| unparsed entities | 1つ1つのDTDの中で宣言された解析されない実体を表す実体情報項目の順序なしセット |
| base URI | ドキュメント実体の基底URI |
| character encoding schema | ドキュメント実体が表現された場での文字エンコーディングスキームの名前 |
| standalone | ドキュメントのスタンドアロン状態を表すYesまたはnoの指示 |
| version | ドキュメントのXMLのバージョンを表す文字列 |
表7:要素情報項目の主なプロパティ
| プロパティ | 説明 |
| local name | 要素名のローカル部分 |
| namespace name | 要素の名前空間 |
| prefix | 要素の名前空間接頭辞 |
| children | ドキュメント順で順序付けられた子となる情報項目のリスト |
| attributes | 属性情報項目の順序なしセット |
| parent | この情報項目の親となるドキュメント情報項目、あるいはエレメント情報項目 |
表8:属性情報項目の主なプロパティ
| プロパティ | 説明 |
| local name | 要素名のローカル部分 |
| namespace name | 要素の名前空間 |
| prefix | 要素の名前空間接頭辞 |
| normalized value | 正規化された属性値 |
| owner parent | attributesプロパティとしてこの情報項目を含む要素情報項目 |
表9:文字情報項目の主なプロパティ
| プロパティ | 説明 |
| character code | 文字のISO 10646の文字コード |
| element content whitespace | 文字が要素の内容に出現した空白であるかどうかを示す論理値 |
| parent | この情報項目をchildrenプロパティの中に持つ要素情報項目 |
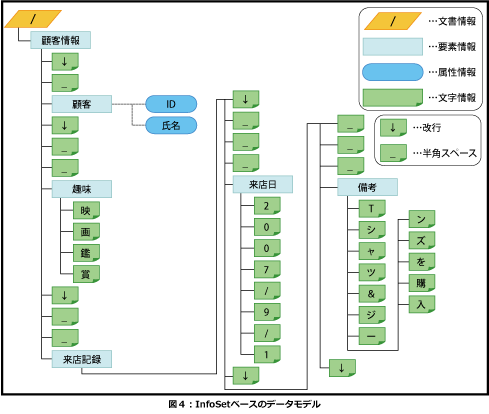
またXPathやDOMをベースにしたデータモデルでは、要素の値を1つのテキストノードとして表現していましたが、InfoSetをベースにしたデータモデルでは、要素の値を文字情報項目として1つ1つの文字を「"映"」「"画"」「"鑑"」「"賞"」(実際にはISO 10646の文字コードに置き換えられます)などのように分解して表現します。ただし、InfoSetベースのデータモデルを採用しているXMLデータベースにおいて、要素の値を1文字ずつ分解して表現するかどうかは、その実装に依存します。
ここまで、XMLDBに格納される際のデータモデルについて解説してきましたが、理解できたでしょうか。以降では、ここまで解説してきたデータモデルの知識を踏まえて、XMLDBに格納されたデータを取り出す際のデータの再現性について解説します。
データの再現性
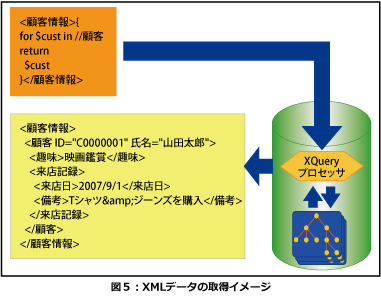
XPathをベースにしたデータモデル、DOMをベースにしたデータモデル、InfoSetをベースにしたデータモデルを持つ3つのXMLDBにLIST1の顧客情報XMLデータが格納されています。ここではDOMをベースにしたデータモデルを持つXMLデータベースにおいて、無意味な空白文字を削除しないこととします。それぞれのXMLデータベースから顧客情報XMLデータを取り出すイメージを図5に、取り出した結果をLIST2~4に示します。
LIST2:XPathベースのXMLDBから取り出した顧客情報XMLデータ
<顧客情報>
<顧客 ID="C0000001" 氏名="山田太郎">
<趣味>映画鑑賞</趣味>
<来店記録>
<来店日>2007/9/1</来店日>
<備考>Tシャツ&ジーンズを購入</備考>
</来店記録>
</顧客>
</顧客情報>LIST3:DOMベースのXMLDBから取り出した顧客情報XMLデータ
<顧客情報>
<顧客 ID="C0000001" 氏名="山田太郎">
<趣味>映画鑑賞</趣味>
<来店記録>
<来店日>2007/9/1</来店日>
<備考><![CDATA[Tシャツ&ジーンズを購入]]></備考>
</来店記録>
</顧客>
</顧客情報>LIST4:InfoSetベースのXMLDBから取り出した顧客情報XMLデータ
<?xml version="1.0" encoding="Shift_JIS" ?>
<顧客情報>
<顧客 ID="C0000001" 氏名="山田太郎">
<趣味>映画鑑賞</趣味>
<来店記録>
<来店日>2007/9/1</来店日>
<備考>Tシャツ&ジーンズを購入</備考>
</来店記録>
</顧客>
</顧客情報>次にLIST5、LIST6の顧客情報XMLデータを見てみましょう。
LIST5:空要素を持つ顧客情報XMLデータ(1)
01 <顧客情報>
02 <顧客 ID = "C0000001" 氏名 = "山田太郎">
03 <趣味/>
04 <来店記録>
05 <来店日>2007/9/1</来店日>
06 <備考><![CDATA[Tシャツ&ジーンズを購入]]></備考>
07 </来店記録>
08 </顧客>
09 </顧客情報>LIST6:空要素を持つ顧客情報XMLデータ(2)
01 <顧客情報>
02 <顧客 ID="C0000001" 氏名="山田太郎">
03 <趣味></趣味>
04 <来店記録>
05 <来店日>2007/9/1</来店日>
06 <備考>Tシャツ&ジーンズを購入</備考>
07 </来店記録>
08 </顧客>
09 </顧客情報>Canonical XML
Canonical XMLとは、XMLで記述された文書を正規化する方法を定義しており、この技術を使用することで、論理的に同じ内容を持つXML文書を必ず物理的にも同じ内容を持つXML文書にできます。Canonical XMLの規格では正規化のルールが定義されており、主なルールは次のとおりです。
XMLDBもしくはXMLデータを登録するアプリケーションなどがCanonical XMLに対応していれば、対象となるXMLデータをCanonical XMLで正規化された状態で格納できます。Canonical XMLを使用することで一定のルールに従ったXMLデータをXMLデータベースに格納でき、またXML宣言や文字エンコーディング方式の違いなども吸収しますので、データの再現性も向上させることができます。
ちなみに、LIST5の顧客情報XMLデータをCanonical XMLを使って正規化すると、LIST6と同じ表現のXML文書になります。
今月の確認問題
ここまで、XMLDBのデータモデルの種類と概要、データの再現性について解説してきました。今回解説した内容についてしっかりと理解できているかどうか、確認問題でチェックしてみましょう。
問題1
次の商品データXML文書をXMLDBに格納する場合、格納したデータをXML形式で取り出すにはどのデータモデルが良いか、正しいものを以下の選択肢の中から選んでください。
ただし、取り出したXMLデータには完全な再現性を求めないものとし、XML形式であれば良いとします。
[ 商品データXML文書 ]
<商品>
<商品名 ID="Y01_001">Yシャツ</商品名>
<価格 単価="円">7900</価格>
<備考><![CDATA[青&白のストライプ]]></備考>
</商品>- XPathをベースにしたデータモデル
- DOMをベースにしたデータモデル
- InfoSetをベースにしたデータモデル
- 選択肢A~Cのデータモデルのいずれか
解説
XPath、DOM、InfoSetをベースにしたデータモデルの特徴的な違いは要素の内容の扱いです。XPathをベースにしたデータモデルは要素の内容を1つの「テキストノード」として、DOMをベースにしたデータモデルも1つの「Textノード」とCDATAセクションで記述されている内容は1つの「CDATASectionノード」として、InfoSetをベースにしたデータモデルはXML文書中の空白文字と要素の内容の1文字1文字を「文字情報項目」として扱います。問題文中には「取り出したXMLデータには完全な再現性を求めないものとし、XML形式であれば良いとします」とありますので、XPath、DOM、InfoSetをベースにしたデータモデルのいずれかで良いことになります。よって正解はDとなります。
問題2
次の商品データXML文書をCanonical XML規格によって正規化した場合、正規化後のXML文書として正しいものを選択してください。
[ 商品データXML文書 ]
<商品>
<商品名 ID = "Y01_001">Yシャツ</商品名>
<価格 単価 = "円">7900</価格>
<備考1><![CDATA[青&白のストライプ]]></備考1>
<備考2/>
</商品><商品>
<商品名 ID="Y01_001">Yシャツ</商品名>
<価格 単価="円">7900</価格>
<備考1><![CDATA[青&白のストライプ]]></備考1>
<備考2></備考2>
</商品><商品>
<商品名 ID="Y01_001">Yシャツ</商品名>
<価格 単価="円">7900</価格>
<備考1>青&白のストライプ</備考1>
<備考2></備考2>
</商品><商品>
<商品名 ID="Y01_001">Yシャツ</商品名>
<価格 単価="円">7900</価格>
<備考1>青&白のストライプ</備考1>
<備考2/>
</商品><商品>
<商品名 ID="Y01_001">Yシャツ</商品名>
<価格 単価="円">7900</価格>
<備考1><![CDATA[青&白のストライプ]]></備考1>
<備考2/>
</商品>解説
Canonical XML規格によってXML文書を正規化する場合、一定のルールがあります。その主なルールとは、次のとおりです。
元となるXML文書では、属性名と属性値の間にはスペースが入り、「備考1」要素の内容がCDATAセクションで記述されており、「備考2」要素は空要素タグで記述されています。これらをCanonical XML規格のルールに従って正規化するとBが正しい結果となります。Aは「備考1」要素の内容がCDATAセクションのまま、Cは「備考2」要素が空要素タグのまま、Dは「備考1」要素の内容がCDATAセクションのままで、「備考2」要素が空要素タグのままになっていますので誤りです。よって正解はBとなります。
問題3
データモデル:XML Information Set(InfoSet)ベース
改行やタブなどの無意味な空白の処理:削除する
妥当性の検証:登録時に行なう
上記の仕様を持つXMLDBに、次のXML文書「product.xml」を登録します。その際にprice要素はどのように登録されるか、正しいものを選択してください。
XML文書 [ product.xml ]
<!DOCTYPE product [
<!ELEMENT product (name,price)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<product>
<name>
腕時計
</name>
<price> open </price>
</product>- <price> open </price>
- <price> open </price>
- <price>open</price>
- 要素の内容に改行や半角スペースなどの空白文字は記述できないため、エラーとなる
解説
XML Information Set(InfoSet)データモデルでは、空白文字を含めてすべて「文字情報項目」として情報を持ちます。DTDの定義がある場合、「文字情報項目」の「element content whitespace」プロパティによって、無意味な空白(改行やタブなど)かどうかを判断できます。ここでは無意味な空白を削除できるようになっています。無意味な空白とは、ある要素が子要素のみを持つ(この場合はproduct要素がname要素、price要素のみを持ち、文字を直接持たない)場合に、子要素と子要素の間などに記述された改行やインデントのことで、要素の内容に記述されている改行や半角スペースなどではありません。B、Cは要素の内容の半角スペースが削除されており、要素の内容の空白文字は無意味な空白ではありませんので誤りです。Dは要素の内容に改行や半角スペースなどの空白文字を記述できますので誤りです。よって正解はAです。
* * *
今回はXMLデータの入出力について、XMLDBのデータモデルと格納されたXMLデータを取り出す際のデータの再現性について解説しましたが、きちんと理解できましたか。データモデルについては各データモデルの特徴と違いをしっかりと理解しておきましょう。データの再現性については、どのレベルまでデータを再現させるかによってデータモデルや格納方法が変わること、Canonical XML規格を使用し、XMLデータの再現性を向上させることができることの2点もしっかりと理解しておきましょう。 次回はXQueryインジェクションについて解説します。
野中康弘(のなかやすひろ)
2004年よりインフォテリア株式会社 教育部に勤務。主にインフォテリア認定トレーニングセンターで開催されているXML教育のテキスト開発/改訂に従事。最近、微妙な三段腹を解消するためにスポーツジム通いを再開。3ヶ月経ったが、週1回ペースのせいか、あまり成果が出ていない。
<掲載> P.201-207 DB Magazine 2007 December
XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~ 記事一覧へ戻る
![]()
