XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~
第3回 XQueryのデータモデルと型
データディレクトテクノロジーズ株式会社(現:日本プログレス株式会社)
山田敏彦 YAMADA, Toshihiko
前回はXQueryの全体像を構文とプロセッシングモデルの両面から概観したので、今回はXQueryでポイントとなる機能や文法に焦点を絞って解説していきます。前回に引き続きXDM(XQuery 1.0 and XPath 2.0 Data Model)の解説が中心になりますが、XDMを押さえてしまえばXQueryの半分は理解できたようなものです。誌面の都合もありすべては解説しきれませんが、ここでしっかりと基礎を固めておきましょう。
XQueryのデータモデルと型
前回、XDM(XQuery 1.0 and XPath 2.0 Data Model)インスタンスの各ノードはXML Schemaの型情報を持つこと、XQueryプロセッサはXDMインスタンスに対して処理を行ない、結果を別のXDMインスタンスとして生成することを解説しました。XQueryのクエリの結果は常にシーケンスとして返されます。つまり、XMLを抽象化したものがXML Infosetであるように、シーケンスを抽象化したものがXDMなのです。
XQueryの型
XDMでは、XSLT 2.0、XPath 2.0、XQ uery 1.0に共通のデータモデルと、データモデルで使用する型を定義しています。全体を俯瞰してみましょう。図1にXQueryの型の階層図を示します。
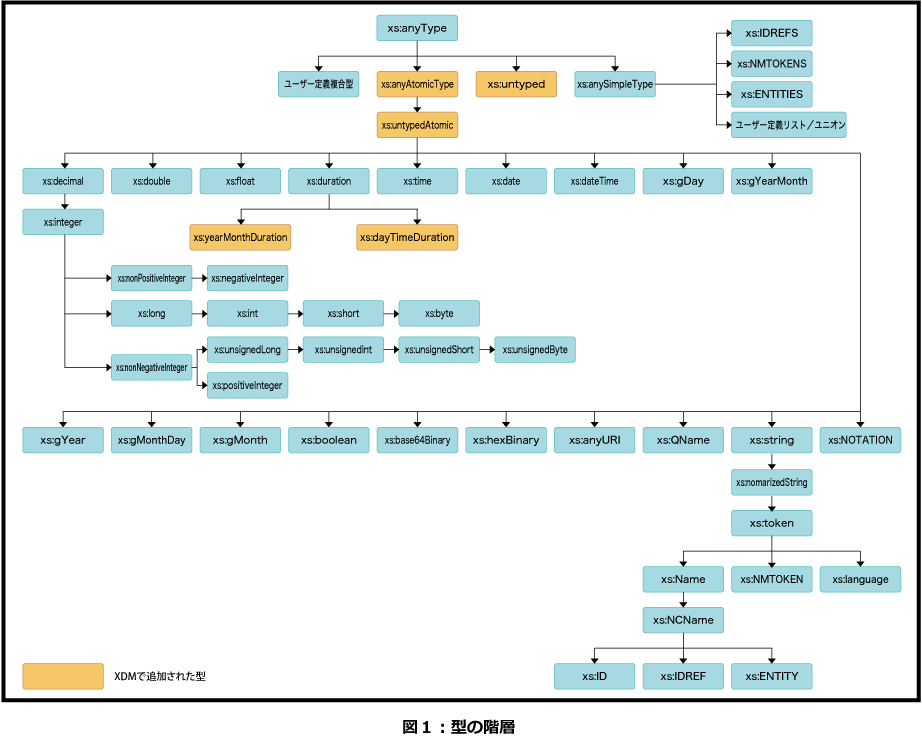
※画像をクリックすると拡大表示されます
注1:古いワーキングドラフトに準拠した実装では接頭辞に「xdt:」を使用する場合があります。
以下に、XDMで追加された型を示します。
● xs:untyped
XML Schemaによる妥当性の検証が行なわれていない要素ノードに割り付けられる型です。ノードについては後述します。
● xs:untypedAtomic
XML Schemaによる妥当性の検証が行なわれていないアトミック値に割り付けられる型です。アトミック値とはアトミック型(注2)のインスタンスで、例えば数値リテラル(注3)や文字列リテラルがアトミック値にあたります。
注2:XML Schemaで定義されている基本型とXDMで追加されたxs:untyped以外の4つの型、およびそれらから派生した型のことを言い、本質的な構造を持たない基本的な型です。
注3:数値リテラルとは、数値を表わす文字列を直接コードの中に記述したもののことです。例えば、「3.14E05」や「3200」が数値リテラルにあたります。
● xs:anyAtomicType
すべてのアトミック型のベースとなる型です。
● xs:dayTimeDuration
xs:duration型から派生した型です。日、時、分、秒の値のみを持ちます。
● xs:yearMonthDuration
xs:duration型から派生した型です。年、月の値のみを持ちます。
XQueryの型とXDMの構造
通常意識して使用するのは前述した型ですが、シーケンスとシーケンスの項目、XDMのノードもXQueryでは型を持つデータとして扱います。シーケンスを表わす型を「シーケンス型」、シーケンスの項目を表わす型を「アイテム型」、ノードを表わす型を「ノード型」と呼びます。これらの型はXDMの構造を反映していますので、少し詳しく見てみましょう。
ノード型
ノード型はXDMを構成するノードを表わす型です。ドキュメントノード、要素ノード、テキストノード、属性ノード、コメントノードなどの種類があり、それぞれが親ノードや子ノードの情報、XDM生成時に割り付けられた型の情報などを固有のプロパティとして持ちます。表にXDMのノードの種類を示します。
表:XDMのノード
| ノード種類 | 説明 |
| ドキュメントノード | 完全なXMLドキュメント全体を表わすノード |
| 要素ノード | XMLドキュメントの個々の要素を表わすノード |
| 名前空間ノード | 要素に関連付けられた名前空間を表わすノード |
| 属性ノード | 要素内の個々の属性を表わすノード |
| コメントノード | コメントを表わすノード |
| 処理命令ノード | 「<?」「>?」で囲まれた処理命令を表わすノード |
| テキストノード | タグで囲まれた文字列全体を表わすノード |
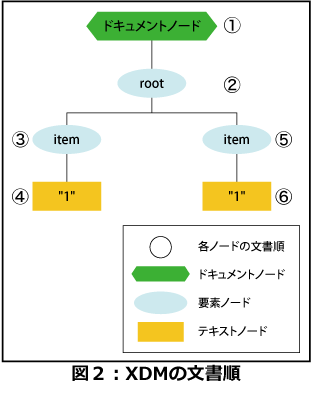
ノードについて注意しなければいけないことは、各ノードに一意の順序が付与されることです。この順序を「文書順(Document order)」と呼びます。また、たとえ同じ型の同じデータを持っていても、各ノードはユニークに識別されます。ですから、以下のクエリの処理結果はfalseになります(「is」演算子については今月の練習問題を参照してください)。
let $d := fn:doc("fugahoge.xml"),
$a := $d/item[1],
$b := $d/item[2]
return $a is $b<root><item>1</item>
<item>1</item></root>- ルートノードは必ず1番目のノードになる
- すべてのノードは自分の子孫よりも若い文書順を持つ
- 名前空間ノードは関連付けられている要素ノードのすぐ次の文書順を持つ。名前空間ノード同士の文書順は実装依存
- 属性ノードは、名前空間ノードがあればその次の文書順を持ち、なければ要素ノードの次の文書順を持つ。属性ノード同士の文書順は実装依存
- 兄弟関係にあるノードの文書順は親ノードのプロパティに現われる順(XMLドキュメントから生成した場合は記述順)になる
- 文書順の若い兄弟ノードに子孫があれば、その子孫は文書順の若くない兄弟ノードよりも若い文書順を持つ
アイテム型
アトミック型とノード型の上位の型で、シーケンスの項目を表わします。つまり、シーケンスの項目として許されるのは任意のアトミック値とノード値です。シーケンスは含まれないことに注意してください。
任意のアイテム値は、そのアイテムのみを持つ長さが1のシーケンスと等値です。例えば、「("1")」は「"1"」と同じことになります。試しに、次の式を実行してみてください。
if(("1") = "1") then "等値です"
else "等値ではありません"シーケンス型
シーケンスを表わす型です。シーケンスは順序を持った0個以上のアイテム値のリストです。個々のアイテム値を「シーケンスの項目」と呼びます。
シーケンスの項目にシーケンスを記述した場合、内側のシーケンスが展開されます。例えば、「(1,(2,3,4),5)」は「(1,2,3,4,5)」と等値になります(エラーにはなりません)。つまりシーケンスの入れ子構造を作ることはできません。アイテム型はアトミック型とノード型の上位の型ですから、アトミック値とノード値を1つのシーケンスに混在させることができます。シーケンスのすべての項目の型が一致する必要もありません。
さて、シーケンスは項目としてノード値を持つことができますから、1つのXDMインスタンスに複数のノード木が含まれる可能性があります。以下のようなシーケンスを抽象化したXDMでは、最初のroot/itemノードと2番目のroot/itemノードの文書順をどのように決めるのでしょうか。
( <root><item>1</item></root>,
<root><item>1</item></root> )「T1のルートノード」<「T1の最初のノード」<…<「T1のn番目のノード」< … <「T1の最後のノード」<「T2のルートノード」<…<「T2のn番目のノード」<…<「T2の最後のノード」
最後に、項目としてノードを含むシーケンスのノード同士の比較について考えてみましょう。次のクエリはどのような結果を返すでしょうか。読み進む前に少し考えてみてください。
let $d := ( <root><item>1</item></root>,
<root><item>1</item></root> ),
$a := $d[1]/item,
$b := $d[2]/item
return $a is $b一方、次のクエリは同じノードを比較していますのでtrueを返します。
let $d := ( <root><item>1</item></root>,
<root><item>1</item></root> ),
$a := $d[1]/item,
$b := $d[1]/item
return $a is $b今月の確認問題
ここまで、XQueryのデータモデルと型を解説してきました。ここで、今回解説した内容について、しっかりと理解できているかどうかを確認問題でチェックしてみましょう。
問題1
次のsample.xmlに関する各選択肢のうち、誤っているものを2つ選択してください。ただし、XQueryプロセッサはfn:doc関数でsample.xmlを正常に読み込むことができるものとします。
また、xs接頭辞は、XML Schema名前空間を示すものとします。
[ sample.xml ]
<sample date="2007-05-01">
<value>5</value>
<value>5</value>
<value>8</value>
</sample>- 次のXQueryによる問い合わせの実行結果は「false」である
fn:doc("sample.xml")//value[1] is fn:doc("sample.xml")//value[2] - 次のXQueryによる問い合わせの実行結果は「false」である
fn:doc("sample.xml")//value[1]/text() is fn:doc("sample.xml")//value[2]/text() - sample.xmlから生成されるXDM(XQuery 1.0 and XPath 2.0 Data Model)のdate属性の型はxs:string型である
- sample.xmlから生成されるXDM(XQuery 1.0 and XPath 2.0 Data Model)の1番目のvalue要素の型はxs:string型である
解説
XQueryプロセッサが問い合わせ先XMLからデータモデル(XDM)を生成した場合、XDM内のすべてのノードはユニークに識別されます。このときXQueryの「is」演算子では、そのユニーク性に基づいて同一ノードであるかどうかが比較されます。選択肢のAとBで示されている各々のノードはすべて異なるノード(テキストノードの場合も異なるテキストノード)なので、どちらも結果は「false」です。XDMを生成する際にXML Schemaの情報がなく、XMLの妥当性が検証されていない場合は、属性ノードは一律にxs:untypedAtomic型が割り当てられ、要素ノードにはxs:untyped型が割り当てられます。したがって、正解はCとDになります。
問題2
次のsample.xmlからXDM(XQuery 1.0 and XPath 2.0 Data Model)を生成した場合に関する以下の説明のうち、誤っているものを1つ選択してください。
ただし、XQueryプロセッサはsample.xmlとsample.xsdを正常に読み込むことができ、XDM生成時にXMLの妥当性を検証するものとします。
[ sample.xml ]
<sample date="2007-05-01">
<value>5</value>
<value>5</value>
<value>8</value>
</sample>[ sample.xsd ]
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="sample" type="SampleType"/>
<xs:complexType name="SampleType">
<xs:sequence>
<xs:element name="value" type="xs:int"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="date" type="xs:date"
use="optional"/>
</xs:complexType>
</xs:schema>- sample要素の型はSampleType型である
- date属性の型はxs:date型である
- 1番目のvalue要素の型はxs:untyped型である
- 1番目のvalue要素の値はxs:int型である
解説
XDMを生成する際にXML SchemaによるXMLの妥当性が検証された場合は、XDMの各要素や属性に適切なXML Schemaの型が割り当てられます。sample要素の型はXML SchemaでSampleType型と定義されており、date属性の型はxs:date型と定義されています。value要素についてもXML Schemaでxs:int型と定義されていますので、value要素の型はxs:int型です。さらに型付けされたノードは型付けされたアトミック値を持っており、設問の例ではDのようにvalue要素の値もxs:int型です。同様に、date属性の型はxs:date型であり、date属性の値もxs:date型です。したがって、正解はCです。
* * *
今回はXDMと型について解説しました。XML Schemaから導入された型についてはほとんど触れていませんが、XQueryで扱いが変わるわけではありません。XDMノードの基本的な構造をしっかりとつかんでおいてください。
次回はXPath 2.0の検索式について、XPath 1.0との違いを中心に説明したいと思います。
山田敏彦 (やまだとしひこ)
慶應義塾大学理工学部卒、日立ソフト、サイベースなどを経て2003年より現職。10年ほど前に治療した虫歯が再発して歯茎が腫れあがってしまい、飲酒すると激しく痛むので、ここしばらくお酒を控えています。皆さんも歯の健康には十分注意してください。
<掲載> P.208-212 DB Magazine 2007 July
XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~ 記事一覧へ戻る
![]()
