XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~
第2回 XQueryの概要
データディレクトテクノロジーズ株式会社(現:日本プログレス株式会社)
山田敏彦 YAMADA, Toshihiko
今回から数回にわたって、プロフェッショナル(DB)試験のメインテーマとも言える「XQuery」について、大まかな概要と文法、クエリの動作などについて解説します。今回は初めですので、XQueryの詳細というよりも、なるべく全体像を理解できるように、具体的なコード例を示しながら説明を進めていきます。また、必要に応じてXQueryの背後にある考え方についても紹介します。抽象的な説明が多くなるため、分かりにくい部分もあるかもしれませんが、頑張ってついてきてください。
最近話題のXQueryとは
最近、目に触れる機会が多くなったXQueryですが、実は10年近い歴史のある言語です。XQueryの仕様検討は1998年に米国ボストンで開かれた「QL98:Query Languages Work shop」で始まりました。W3Cでは「Quilt」と呼ばれるXML問い合わせ言語をベースに仕様を拡充していく、というプロセスで検討が進められ、ワーキングドラフトが公開されたのは2001年のことです。ですから、QL98から10年、ワーキングドラフトの公開からでも7年の歳月を費やして検討されてきたことになります。
このような経緯で策定されたXQueryは、XML文書だけでなくRDBへの問い合わせもサポートしています。実際、W3Cが公開しているドキュメントでは随所にデータソースとしてのRDBに触れており、RDBのデータとSOAPメッセージをJOINしてHTMLに整形して出力する、などという処理も簡単に実現できます。
W3Cが公開しているXQueryに関連するドキュメントは17本あり、そのうち8本が勧告、その他はワーキングドラフトとなっています(2007年3月1日現在)。これらにはXPath 2.0、XSLT 2.0の仕様書も含まれています。特に関数や演算子、データモデルはXPath 2.0と共通の仕様になっています。
コードでXQueryを理解する
言葉で説明してもなかなか分からないと思いますので、最初にXQueryのコードを見て、全体の感じをつかんでみましょう。LIST1に簡単なサンプルを示します。
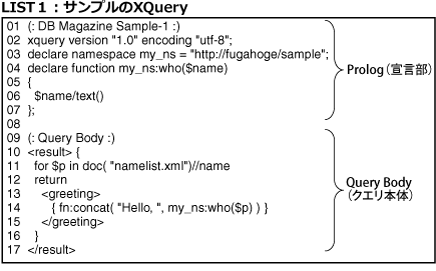
LIST1はLIST2のXML文書に問い合わせを行ない、LIST3のようなXML文書を出力するクエリです。
LIST2:サンプルのXMLデータ(namelist.xml)
<?xml version="1.0" encoding="UTF-8"?>
<namelist>
<name>Hiro</name>
<name>Toshi</name>
<name>Mayumi</name>
</namelist>LIST3:出力結果
<result>
<greeting>Hello, Hiro</greeting>
<greeting>Hello, Toshi</greeting>
<greeting>Hello, Mayumi</greeting>
</result>XQueryのクエリは各種の宣言を行なう「Prolog」と、問い合わせを行ない出力を編集する「Query Body」からなります。Prologは省略可能ですが、Query Bodyは省略できません。
各種の宣言を行なう「Prolog」
まず、LIST1のPrologの内部を見てみましょう。Prologでは各宣言を「;」で分離します。
● コメント
1行目と9行目はコメントです。コメントは「(:」と「:)」で囲まれた任意の文字列で、処理に影響を与えない空白文字が存在できる位置であればどこにでも置くことができます。ここで言う空白文字とは、タブ、改行、復改、スペースを意味します。
LIST4にコメントの例をいくつか挙げます。
LIST4:コメントの例
(: これはコメントです :)
(1, (: これはシーケンスの中のコメントです (: コメントは入れ子にできます :) :) 2, 4)
<tag1 attr1='(: これはコメントではありません :)' />2行目はXQuery宣言です。準拠するXQueryのバージョンと使用しているエンコードを宣言します。「encoding」以降は省略可能です。
● 名前空間宣言
3行目は名前空間宣言と呼ばれ、クエリで使用する名前空間を宣言します。
● ユーザー定義関数宣言
4~7行目はユーザー定義関数宣言です。ユーザー定義関数は組み込み関数と同様にQuery Bodyやほかのユーザー定義関数から呼び出すことができます。サンプルではパラメータとして受け取った要素が直接持っているテキストを抽出しています。
● 変数
「$」で始まる名前は変数名です。LIST1では6行目や11行目で変数が使用されています。ただし、「変数」とは言ってもXQueryでは値を変更できません(コラム 「XQueryと関数型プログラミング」 参照)ので、「定数」とでも呼んだほうがしっくり来るかもしれません。
問い合わせ/出力を行なう「Query body」
続いて、Prologと同じようにQuery Bodyの内部も見てみましょう。
● ダイレクトコンストラクタ
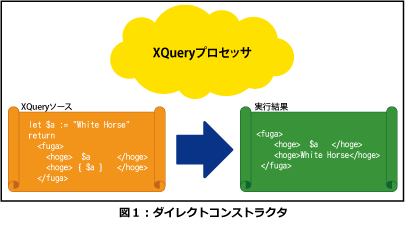
10行目、13行目のようにクエリの中にタグが現われると、XQueryプロセッサ(X Queryのクエリを解釈して処理を行なうプログラム)により同じ名前のタグを生成します。
このとき、開始タグと終了タグの間にある内容をタグの内容とみなして、まったく同じ内容を生成するように記述します。つまり、クエリ中にタグを記述することで生成したい要素のタグ名や内容を指定できるのです。これを「ダイレクトコンストラクタ」と呼びます。タグの内容を動的に生成したい場合は、開始タグと終了タグの間に「{ }」で囲んだ任意のXQuery式を記述します。図1にダイレクトコンストラクタによる実行結果を示します。
11行目の「doc(……)」は、指定されたURIからXMLドキュメントを読み込む関数で、読み込んだドキュメントを返します。
● concat関数
14行目の「fn:concat(……)」は、文字列を連結する関数です。ユーザー定義関数my_ns:whoが返した文字列と「Hello,」を連結して「Hello, xxxx」という文字列を返しています。
● FLWOR式
11~15行目までの全体を「FLWOR(フラワー)式」と呼びます。LIST1では、いくつかの構成要素が省略されています。
FLWOR式はXQueryの最も重要な構文の1つで、SQLになぞらえるとSELECT文とFETCH文を合わせたような機能を提供します。11行目のfor句では検索対象がnamelist.xmlというファイルに保存されているXMLドキュメントに現われる「name」という要素すべてであることを示しています。
なお、検索対象の要素を指定する際はXPath式を用いていることに注意してください。前回の記事でも触れていますが、XPath 2.0はXQuery 1.0のサブセットとして設計されています。
12~15行目ではreturn句でダイレクトコンストラクタを使用して<greeting>タグを生成しています。FLWOR式はreturn句の処理結果を返しますので、11~15行目全体でnamelist.xmlに現われるname要素のすべてについて<greeting>タグを生成する、という意味になります。
さて、ここまで駆け足でLIST1のサンプルXQueryクエリを見てきました。細かい疑問が残っていたり、いまひとつ腑に落ちない部分があるとは思いますが、今のところは全体の流れが分かればそのままで構いません。
プロセッシングモデルと式のコンテキスト
XQueryプロセッサがクエリを評価してXMLを処理し、出力を得る際に内部ではどのような処理が行なわれているのでしょうか。W3Cでは、このXQueryプロセッサの処理をモデル化しています。これを「プロセッシングモデル」と言います。
クエリを処理する際には、環境情報のような対象の式以外の情報も参照する必要があります。このような情報を「式のコンテキスト」と呼び、クエリを解析する際に必要となる情報を「静的コンテキスト」、クエリを評価する際に必要となる情報を「動的コンテキスト」と呼びます。コンテキストはプロセッシングモデルの重要な構成要素の1つです。
それでは、プロセッシングモデルについて簡単に見ていきましょう。
データモデルの生成
問い合わせ先XMLからデータモデル(XQuery 1.0 and XPath 2.0 Data Model。以下、XDM)のインスタンスを生成します。正確には、XML InfoSetやPSVI(注1)をXDMインスタンスに変換します。
注1:Post-Schema-Validation InfoSet。XML Sche maによって妥当性が検証されているInfoSetで、各ノードにはXML Schemaに基づいた型情報が付加されています。XDMはPSVIをシーケンス対応に拡張したものと考えることもできます。
XDMとはなんでしょうか。一言で言えば「処理対象のXMLを論理的な木構造で表現し、各要素や属性に適切なXML Sche maの型を割り当てたもの」です。妥当性が検証されていないため適切な型情報が利用できない場合は属性ノードには一律xs: untypedAtomic型が、要素ノードにはxs: untyped型が割り当てられ、部分的に妥当性が検証されている要素ノードの場合はxs:anyType型が割り当てられます。LIST2を少し変更したLIST5のXML文書と対応するLIST6のXML Schemaから生成されるXDMの模式図を図2に示します。XDMはXML文書以外(RDBなど)から直接生成しても構いません。
LIST5:LIST2(namelist.xml)の改訂版
<?xml version="1.0" encoding="UTF-8"?>
<namelist xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance
xsi:noNamespaceSchemaLocation="namelist.xsd">
<name gender="male">Hiro</name>
<name gender="male">Toshi</name>
<name gender="female">Mayumi</name>
</namelist>LIST6:LIST5に対応するXML Schema
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="namelist">
<xs:complexType>
<xs:sequence>
<xs:element maxOccurs="unbounded" ref="name"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="name">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="gender" use="required" type="xs:string"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:schema>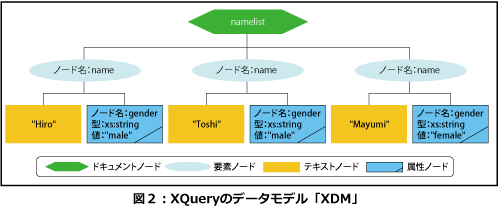
クエリの静的解析
クエリの処理は「静的解析」と「動的評価」の2フェーズに分けて実施されます。静的解析フェーズでは静的コンテキストを作成/参照しながらクエリの内部表現(操作木)を作成します。静的コンテキストは環境情報、Prolog、(importをサポートしている実装では)XML Schemaの型情報、モジュール(注2)を参照して作成されます。
注2:モジュールはユーザーライブラリに相当するもので、ユーザー定義関数の宣言を記述した外部ファイルのことです。Prologでモジュールをimportすることで、モジュール内部の関数をQuery Bodyで使用できるようになります。
これらのうち、importは実装しなくても良い機能なので、モジュールやXML Schemaを参照するか否かは実装依存になります。文法エラーのように、このフェーズだけで発生するエラーを「静的エラー」と呼びます。図3に静的解析の概念図を示します。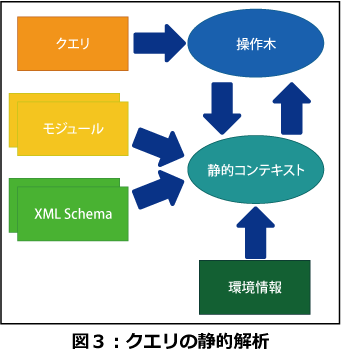
クエリの動的解析
静的解析フェーズでエラーが発生しなかった場合に限り、動的評価フェーズが実行されます。動的評価フェーズでは、操作木に従って問い合わせ先XDMに対する問い合わせを実行します(図4)。
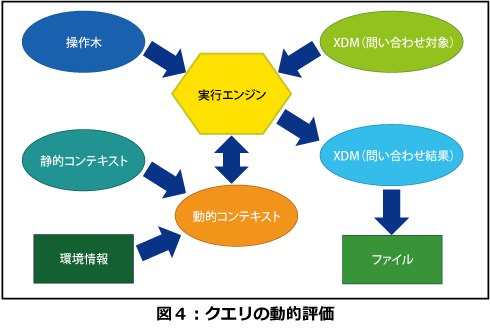
動的評価を実行する際には、操作木や問い合わせ先XDMだけでなく動的コンテキストも参照します。動的コンテキストは、静的コンテキストに実際に変数として割り当てられている値と型のような実行時情報、タイムゾーンや日付時刻などの環境情報を追加して作成されます。
動的コンテキストの内容は処理の実行中に絶えず変化します。0除算エラーのように、このフェーズだけで発生するエラーを「動的エラー」と呼びます。また、処理結果のXDMをファイルに出力することを「シリアライズ」と言います。シリアライズは実装が必須な機能ではありません。
型エラーと静的型付け
「型エラー」は静的解析、動的評価のいずれのフェーズでも発生する可能性があるので動的エラーにも静的エラーにも分類されていませんが、すべての型エラーを静的解析フェーズで検出する実装も許されています。このような機能を「静的型付け」と呼びます。
例として、次の式を評価することを考えてみましょう。
29 + if ( $fuga ) then 30 else "30"
この式は、静的型付けをサポートしていない実装では静的解析フェーズにおいてエラーになりません。$fugaの値によって、実行時に型エラーが発生するか59を返すかが決まります。
一方、静的型付けをサポートした実装では、静的解析フェーズで型エラーが発生します。if式が文字列を返す可能性があるからです。静的型付けもシリアライズ同様、実装が必須な機能ではありません。
今月の確認問題
ここまで、XQueryの概要を解説してきました。ここで、今回解説した内容について、しっかりと理解できているかどうかを確認問題でチェックしてみましょう。
問題1
XQuery 1.0に関する次の説明のうち、誤っているものを1つ選択してください。
- 名前空間などを宣言したり、独自の関数を定義するためのPrologという記法を定義しており、これはクエリ本文よりも前に記述する
- クエリ実行結果を文字列としてシリアライズする方法を定めており、シリアライズ時の条件(文字エンコーディングを何にするかなど)をPrologに宣言する
- クエリの実行結果に影響を与える式のコンテキストを定めており、これには式の静的解析時に利用される静的コンテキストと、式の評価時に利用される動的コンテキストの分類がある
- クエリ実行時のエラーを定義しており、さらに各々のエラーを識別するためのQName(識別のための名前空間と識別コード)を定めている
解説
クエリの実行結果を文字列としてシリアライズする方法についての詳細は、別の仕様書である「XSLT 2.0 and XQuery 1.0 Serialization」で定められています。そしてXQuery 1.0では、XQueryプロセッサに対してシリアライズ機能の実装を要求していません。また、シリアライズ時の条件などの指定方法についても実装側で決めて良いことになっており、Prologに宣言することが定められているわけではありません。したがって、正解はBです。
問題2
XQueryの処理の様子を説明する次の文章のうち、誤っているものを1つ選択してください。
- 処理対象のXMLデータからXDMインスタンスを生成し、そのインスタンスに対してクエリ処理を進める
- DTDで検証された妥当なXMLデータから生成されたXDMの属性ノードは、DTDの型情報(CDATAやNMTOKENなど)を 持つ
- XML Schemaで検証された妥当なXMLデータから生成されたXDMの要素ノードと属性ノードは、XML Schemaの型情報(単純型や複合型など)を持つ
- 処理の過程には静的解析フェーズと動的評価フェーズがあり、静的解析の後に動的評価を行なう
解説
XQueryで生成されるXDMのノードの型情報はXML Schemaから得られますが、DTDからノードの型情報を得ることはできません。例えば、DTDで検証された妥当なXMLデータの属性ノードの型は、特に型情報がないもの(xs:untypedAtomic)としてモデル化されます。CDATAやNMT OKENなどの型情報を持つわけではありません。 一方、XML Schemaで検証された妥当なXMLデータの場合は、XML Schemaに基づいた型情報を得ることができ、それにより型を使用した演算などを行なうことができます。よって正解はBです。
* * *
今回は、イントロダクションということでXQueryの概略を説明しました。多少抽象的な話が混じってしまいましたが、できる限り理解しやすいように解説したつもりです。いかがだったでしょうか。ここで、今回解説したポイントをまとめておきます。
次回は型とデータモデルを説明したいと思います。
山田敏彦 (やまだとしひこ)
慶應義塾大学理工学部卒。日立ソフト、サイベースなどを経て2003年より現職。酒とダーツと煙草を好み、夜な夜な四谷、荒木町界隈を徘徊している。最近の悩みはダーツがbullを囲むこと……。
<掲載> P.189-193 DB Magazine 2007 June
XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~ 記事一覧へ戻る
![]()
